Split string into sentences in javascript
str.replace(/(\.+|\:|\!|\?)(\"*|\'*|\)*|}*|]*)(\s|\n|\r|\r\n)/gm, "$1$2|").split("|")
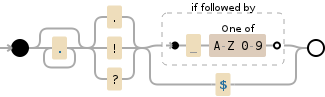
The RegExp (see on Debuggex):
- (.+|:|!|\?) = The sentence can end not only by ".", "!" or "?", but also by "..." or ":"
- (\"|\'|)*|}|]) = The sentence can be surrounded by quatation marks or parenthesis
- (\s|\n|\r|\r\n) = After a sentense have to be a space or end of line
- g = global
- m = multiline
Remarks:
- If you use (?=[A-Z]), the the RegExp will not work correctly in some languages. E.g. "Ü", "Č" or "Á" will not be recognised.
Use lookahead to avoid replacing dot if not followed by space + word char:
sentences = str.replace(/(?=\s*\w)\./g,'.|').replace(/\?/g,'?|').replace(/\!/g,'!|').split("|");
OUTPUT:
["This is a long string with some numbers [125.000,55 and 140.000] and an end. This is another sentence."]
You could exploit that the next sentence begins with an uppercase letter or a number.
.*?(?:\.|!|\?)(?:(?= [A-Z0-9])|$)
Debuggex Demo
It splits this text
This is a long string with some numbers [125.000,55 and 140.000] and an end. This is another sentence. Sencenes beginning with numbers work. 10 people like that.
into the sentences:
This is a long string with some numbers [125.000,55 and 140.000] and an end.
This is another sentence.
Sencenes beginning with numbers work.
10 people like that.
jsfiddle
str.replace(/([.?!])\s*(?=[A-Z])/g, "$1|").split("|")
Output:
[ 'This is a long string with some numbers [125.000,55 and 140.000] and an end.',
'This is another sentence.' ]
Breakdown:
([.?!]) = Capture either . or ? or !
\s* = Capture 0 or more whitespace characters following the previous token ([.?!]). This accounts for spaces following a punctuation mark which matches the English language grammar.
(?=[A-Z]) = The previous tokens only match if the next character is within the range A-Z (capital A to capital Z). Most English language sentences start with a capital letter. None of the previous regexes take this into account.
The replace operation uses:
"$1|"
We used one "capturing group" ([.?!]) and we capture one of those characters, and replace it with $1 (the match) plus |. So if we captured ? then the replacement would be ?|.
Finally, we split the pipes | and get our result.
So, essentially, what we are saying is this:
1) Find punctuation marks (one of . or ? or !) and capture them
2) Punctuation marks can optionally include spaces after them.
3) After a punctuation mark, I expect a capital letter.
Unlike the previous regular expressions provided, this would properly match the English language grammar.
From there:
4) We replace the captured punctuation marks by appending a pipe |
5) We split the pipes to create an array of sentences.