How to fanout an AWS kinesis stream?
There is a github repo from Amazon lab providing the fanout using lambda. https://github.com/awslabs/aws-lambda-fanout . Also read "Transforming a synchronous Lambda invocation into an asynchronous one" on https://medium.com/retailmenot-engineering/building-a-high-throughput-data-pipeline-with-kinesis-lambda-and-dynamodb-7d78e992a02d , which is critical to build a truly asynchronous processing.
There are two ways you could accomplish fan-out of an Amazon Kinesis stream:
- Use Amazon Kinesis Analytics to copy records to additional streams
- Trigger an AWS Lambda function to copy records to another stream
Option 1: Using Amazon Kinesis Analytics to fan-out
You can use Amazon Kinesis Analytics to generate a new stream from an existing stream.
From the Amazon Kinesis Analytics documentation:
Amazon Kinesis Analytics applications continuously read and process streaming data in real-time. You write application code using SQL to process the incoming streaming data and produce output. Then, Amazon Kinesis Analytics writes the output to a configured destination.
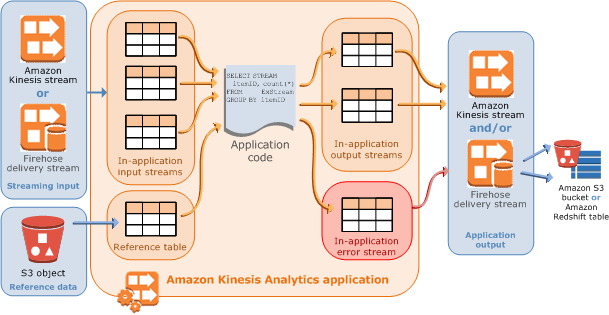
Fan-out is mentioned in the Application Code section:
You can also write SQL queries that run independent of each other. For example, you can write two SQL statements that query the same in-application stream, but send output into different in-applications streams.
I managed to implement this as follows:
- Created three streams: input, output1, output2
- Created two Amazon Kinesis Analytics applications: copy1, copy2
The Amazon Kinesis Analytics SQL application looks like this:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM"
(log VARCHAR(16));
CREATE OR REPLACE PUMP "COPY_PUMP1" AS
INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM "log" FROM "SOURCE_SQL_STREAM_001";
This code creates a pump (think of it as a continual select statement) that selects from the input stream and outputs to the output1 stream. I created another identical application that outputs to the output2 stream.
To test, I sent data to the input stream:
#!/usr/bin/env python
import json, time
from boto import kinesis
kinesis = kinesis.connect_to_region("us-west-2")
i = 0
while True:
data={}
data['log'] = 'Record ' + str(i)
i += 1
print data
kinesis.put_record("input", json.dumps(data), "key")
time.sleep(2)
I let it run for a while, then displayed the output using this code:
from boto import kinesis
kinesis = kinesis.connect_to_region("us-west-2")
iterator = kinesis.get_shard_iterator('output1', 'shardId-000000000000', 'TRIM_HORIZON')['ShardIterator']
records = kinesis.get_records(iterator, 5)
print [r['Data'] for r in records['Records']]
The output was:
[u'{"LOG":"Record 0"}', u'{"LOG":"Record 1"}', u'{"LOG":"Record 2"}', u'{"LOG":"Record 3"}', u'{"LOG":"Record 4"}']
I ran it again for output2 and the identical output was shown.
Option 2: Using AWS Lambda
If you are fanning-out to many streams, a more efficient method might be to create an AWS Lambda function:
- Triggered by Amazon Kinesis stream records
- That writes records to multiple Amazon Kinesis 'output' streams
You could even have the Lambda function self-discover the output streams based on a naming convention (eg any stream named app-output-*).